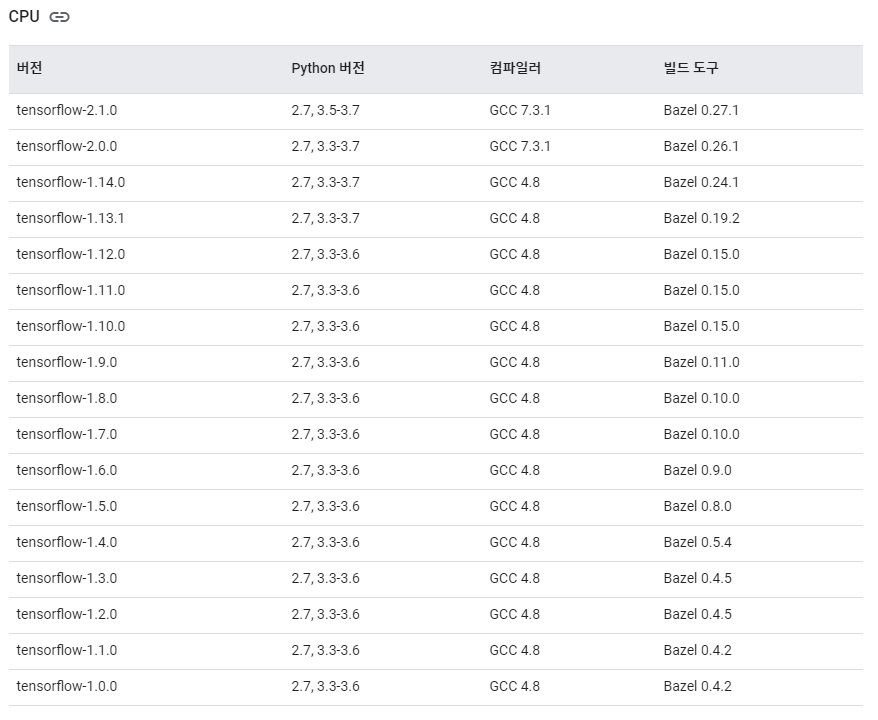
torch.backends.cudnn.benchmark 코드는 True와 False로 설정할 수 있다. 이 코드의 역할은 다음과 같다. 내장된 cudnn 자동 튜너를 활성화하여, 하드웨어에 맞게 사용할 최상의 알고리즘(텐서 크기나 conv 연산에 맞게?)을 찾는다. 입력 이미지 크기가 자주 변하지 않는다면, 초기 시간이 소요되지만 일반적으로 더 빠른 런타임의 효과를 볼 수 있다. 그러나, 입력 이미지 크기가 반복될 때마다 변경된다면 런타임성능이 오히려 저하될 수 있다. https://discuss.pytorch.org/t/what-does-torch-backends-cudnn-benchmark-do/5936/7 What does torch.backends.cudnn.benchmark do? Does it..