Written by Hengsuang Zhao, Xiaojuan Qi, Xiaoyong Shen, Jianping Shi, Jiaya Jia
Abstract
Real-time Segmentation 분야에서는 픽셀단위 라벨 추론에 대한 계산량을 줄이는데 있어, 어려움을 가지고 있다. 계층 단위 Multi-Resolution 브랜치들을 이용하여 적절한 label guidance 방법을 수행하였으며, 이미지 해상도에 따른 다양한 정보들을 Cascaded Fusion 하였다. 제안하는 방법은Cityscapes, CamVid, COCO-Stuff 등에서 빠른 속도와 high quality segmentation 결과를 보이고 있다.
Introduction
CNN-based Semantic Segmentation은 주로 Fully Convolutional Networks(FCNs)를 사용하고 있으며, 결과 정확도를 높이기 위해서는 더 많은 연산이 필요한 것으로 알려져 있다.

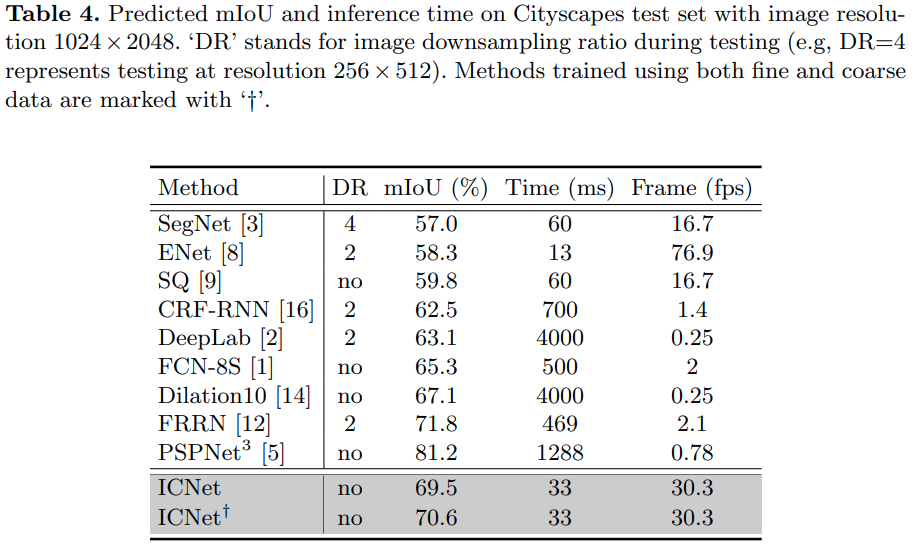
최근 방법들에서 FPS에 따른 Accuracy는 다음과 같으며, 제안하는 방법은 fps대비 높은 정확도를 보이고 있다.
Our Contribution
- Real-time segmentation 방법을 개발하였으며, 고 해상도에서의 정보와 저 해상도에서의 semantic정보를 효율적으로 활용하였다.
- Label guidance로 개발된 cascaded feature fusion 방법은 낮은 계산비용으로 segmentation 예측을 점진적으로 개선시킬 수 있다.
- ICNet은 5배 빠른 속도와 5배 줄어든 메모리를 달성하였다. 또한, 1024x2048에서 높은 정확도 및 30fps의 속도를 보였으며, Cityscapes, CamVid, COCO-Stuff에서 Real-time 성능을 보였다.
Image Cascaded Network

Speed Analysis
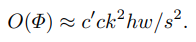
계산 복잡도는 feature map의 해상도(eg. h, w, s=stride)와 커널의 수, 네트워크의 width (eg. c, c')와 관련있다. 위의 그림 1(b)은 두 이미지 해상도에 대한 Time Cost를 보여주고 있다. Blue curve는 1024x2048의 고해상도 입력, Green curve는 512x1024의 입력을 나타낸다. 두개의 커브는 stage4와 stage5에서 같은 spatial 해상도 즉, 원본 이미지의 1/8 해상도이다. 그러나, 연산량은 stage 5가 stage 4에비해 4배 무겁다. 그 이유는 stage 5의 컨볼루션 계층이 입력 채널 c'에 대해, 채널 c의 수를 두배로 늘리기 때문이다.
Network Design
Time buget 분석에 따라, downsampling input, shrinking feature maps과 같은 model compression을 통한 향상 전략을 채택하였다. 본 논문에서는 입력 이미지에 대해 단순히 적용하는 것이 아닌 cascaded feature fusion unit 방법을 채택하여 cascaded label guidance와 함께 학습하였다.
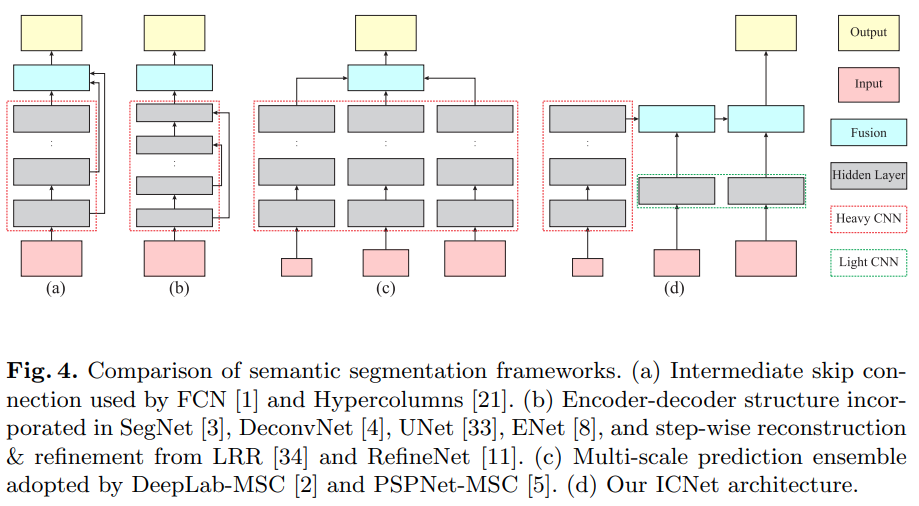
- 그림 2에서처럼, 입력 이미지에 대해 factor 2, 4로 down sampling을 수행하여 cascade input으로 활용한다. 각각의 Medium, High branch에서의 결과들은 Coarse 예측들에 대해 recover, refine하는데 도움을 준다. 고해상도 이미지에 대한 branch는 Light CNN으로 적용하였으며, 다른 branch들은 cascaded-feature-fusion 에 의해 결합되고, cascaded label guidance를 학습시킨다.
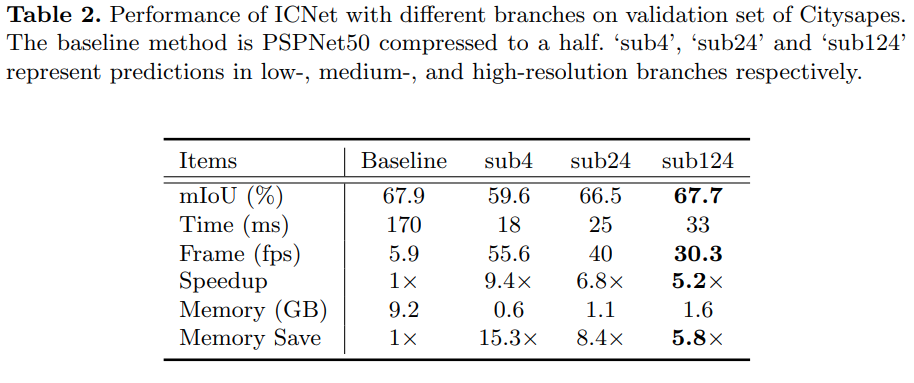
- PSPNet은 50+ layer를 가지고 있지만, cityscapes에서 inference time과 memory는 18ms, 0.6GB이다. 그 이유는 가중치와 계산(in 17layers)는 low-와 medium-이 공유되기 때문이다.
Cascaded Feature Fusion
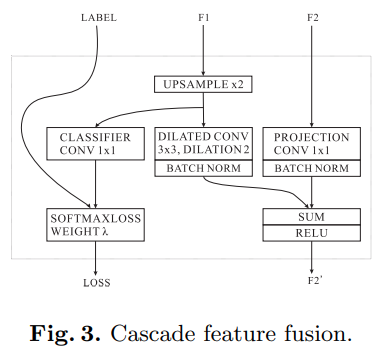
CFF의 구조는 그림 3과 같으며 3개의 COMPONENT로 구성되어 있다. 먼저, F1에서 2배 upsampling 수행하여 F2와 동일한 크기를 만들어 준다. 그 후, C3 x 3 x 3의 dilated convolution layer를 통해 refine한다. C3x1x1에 의해 projection된 F2는 같은 수의 채널을 가진 F1과 결합되며, element wise - ReLU를 거치며 C3xH2xW2를 얻는다. 또한, F1의 학습을 향상시키기 위해 auxilary guidance를 활용하였다.
Cascaded Label Guidance
각 브랜치들에 대한 학습을 향상시키기 위해 cascaded 전략을 사용하였으며, 파라미터를 활용한 weighted softmax cross entropy loss를 각 브랜치에 대해 수행하였다. 테스트시에는 low와 medium guidance 연산은 제거되며, 오직 high-resolution 브랜치만 유지한다.

Experiment
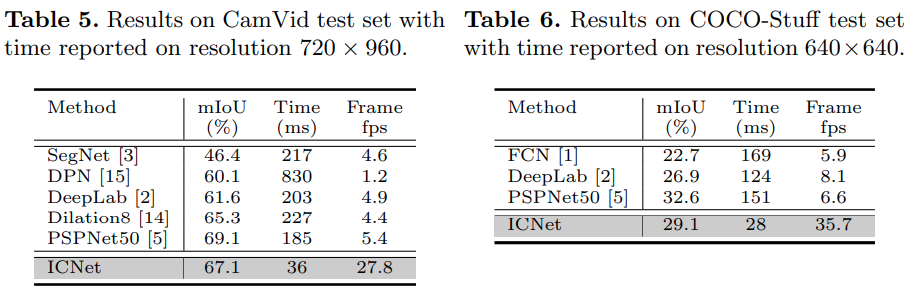
CityScapes(1024x2048) COCO-Stuff (640x640)


CamVid(720x960), COCO-Stuff(640x640)