Written by Davy Neven, Bert De Brabandere, Stamatios Georgoulis, Marc Proesmans, Luc Van Gool
[Abstract]
현대의 접근 방식은 큰 Receptive Field로 인해 이미지에 차선 표시가 없는 경우에도 픽셀 단위 차선 분할을 위해 학습된 딥러닝 모델을 활용합니다. 이러한 장점들에도 불구하고, ego-lane과 같이 사전 정의된 차선이나 고정된 숫자의 차선들을 탐지하는 것에 제한된다. 본 논문에서는 이러한 문제를 보완하고자 각 레인에 대한 instance 분할 문제로 탐지해야 함을 제안하였다. End-to-End 방식을 사용하였으며 원영상에 탐지된 차선을 맞추기 전, 분할된 차선 인스턴스를 매개 변수 화하기 위해 고정된 "bird-eye view"변환 대신 이미지에 조건을 둔 학습된 원근 변환을 적용하였다. 이를 통해, 사전 정의된 고정 변환 방법에 의존하는 기존 접근 방식과 달리 Robust 한 차선 피팅을 보장한다. 또한, 50 fps의 빠른 속도를 보이며 tuSimple 데이터 셋에서 경쟁적인 성능을 보였다.
[Introduction]

Camera-based 차선 탐지는 차량의 위치에 대한 주변환경을 이해하는 데 있어 중요한 센서로 여겨져 왔으며, 차선 이탈이나 trajectory planning decision에서도 중요하다. 기존의 방법들은 차선을 구별하기 위해 color, structure tensor, bar filter 등의 hand-crafted 휴리스틱 한 방법을 취해왔다.
현대에는 pixel-wise lane segmentation의 접근방법을 사용하여 문제를 해결해왔다. 기존의 여러 네트워크가 차선을 더 잘 분할 할 수 있는 능력과는 별개로, 큰 receptive field를 통해 이미지에 lane marking이 없는 경우에도 차선을 추정할 수 있었다. 그러나, 최종 단계에서 생성된 binary segmentation은 각각의 차선들이 다른 인스턴스로 분리되어야 하는 문제를 가지고 있다. 이러한 문제를 다루기 위해 여러 heuristic 한 post processiong 방법들이 발전하였으며, 본 논문에서는 end-to-end 방식으로 다루고자 한다.
Our Contribution
- 차선 변경에 의한 임의의 차선 수를 추론할 수 있는 차선 탐지 문제를 instance segmentation 방법으로 해결하는 multi-task architecture 방법이다. 특히, lane segmentation branch는 dense한 픽셀 당 segmentation을 출력하는 반면, lane embedding branch는 분할된 lane 픽셀을 다른 lane 인스턴스로 추가 분리한다.
- 입력 이미지가 주어진 네트워크는 도로 평면 변경(오르막, 내리막 길)에 대해 robust한 lane fitting을 허용하는 원근 변환의 매개변수를 추정한다.
[Method]

"LaneNet"은 binary lane segmentation의 이점과 one-shot instance segmentation을 위해 설계된 clustering loss function과 결합하게 되며, Lanenet의 출력에서 각 차선 픽셀에는 해당 차선의 ID가 할당된다. Lanenet은 차선 당 픽셀 모음을 출력하므로 차선 매개변수화를 얻으려면, 이러한 픽셀들을 곡선에 결합해야 하며 일반적으로는 고정된 파라미터를 이용하여 투영한다. 그러나 모든 이미지에 대해 변환 매개 변수가 고정되어 있기 때문에 평평하지 않은 지면 문제가 발생할 수 있다. 이러한 문제를 해결하기 위해 원근 변환의 매개변수를 추정하는 H-Net이라는 네트워크를 따로 학습시켰다.
Lanenet : 네트워크는 차선 수에 제한을 받지 않으며, 차선 변경에 대해 대처할 수 있다. instance segmentation은 segmentation 및 clustering 두부분으로 구성되며 속도와 정확성 측면에서 성능을 높이기 위해 multi-task 네트워크에서 공동으로 훈련된다.
- binary segmentation : 이진 segmentation map을 출력하도록 훈련되어 어떤 픽셀이 차선에 속하는지 여부를 나타낸다. 또한, 장애물과 같은 물체에 가려진 경우, 점선 또는 희미한 차선과 같은 명시적인 시각적 차선이 없는 경우에도 예측하는 방법을 학습한다. cross-entropy loss를 사용하였으며, 두 클래스(lane/background)가 매우 불균형하므로 bounded inverse class weighting 적용하였다. (참고 2- E-net)
- instance segmentation : one-shot method 기반의 distance metric learning방법을 사용하였으며 real-time 어플리케이션을 위해 특별히 설계되었다. 이 clustering loss function 방법은 각 차선 픽셀이 같을 경우 거리가 작아지게 만들고, 다른 차선일 경우 거리가 더욱 멀어지게 만들었다.
두 개의 terms로 나뉘며, var은 각 차선 픽셀에 대해 mean embedding을 수행한다. 또 다른 dist는 cluster의 center로 모이게 만든다.

- clustering : 반복적인 절차에 의해 발생하며, 모든 차선 embedding이 차선에 할당될 때까지 반복된다. outlier를 임계 값으로 선택하지 않기 위해, 먼저 mean shift를 사용하여 클러스터 중심에 더 가깝게 이동한 다음 임계값을 지정한다.
- network architecture : 차선 탐지는 E-Net기반의 인코더-디코더 구조로 되어있으며, 두개의 branch 네트워크로 수정된다. E-Net의 encoder는 decoder보다 더 많은 파라미터를 가지며, 전체 인코더 부분을 완전 공유할 경우 안 좋은 결과가 발생할 수 있기 때문에, 처음 2단계만 공유하고, 각 분기의 3단계와 디코더는 개별 분기로 남겼다. 마지막 레이어는 1 채널 이미지를 출력하는 반면, embedding 마지막 분기는 N이 임베딩 차원인 N-채널 이미지를 출력한다.
각 지점의 loss term은 동일하게 가중치가 부여되고, 네트워크를 통해 역전파된다.
Curve Fitting Using H-Net : LaneNet의 출력은 차선 당 픽셀 모음이며, 곡선을 표현하는 다항식에 적합하지 않다. 따라서, 고차 다항식을 맞추기 위해서는 "bird's-eye view"표현으로 투영하는 것이다. 여기서 차선은 서로 평행하기 때문에 2차에서 3차 다항식으로 맞출 수 있다. 그러나, 고정된 파라미터는 무한대로 투영되는 소실점의 변화(shifts up, ownwards) 시 오류가 발생한다.
이러한 문제를 해결하기 위해, H-Net에 custom loss function을 사용하였다. 원근 변환 H의 매개변수를 예측하기 위해 end-to-end 학습에 최적화되어있으며 변환된 차선 지점은 2차 또는 3차 다항식이다. 예측은 입력 이미지에 따라 조정되므로 상황의 변화(오르막 or 내리막) 시 정확성을 가지게 된다.
*bird's eye view : 원근감으로 인해 Front 카메라의 경우 이미지에서 평행선이 수렴하는 것처럼 보인다. 평행선을 평행하게 유지하기 위해 "bird's eye view"변환을 사용하게 된다. 변환방법은 두가지가 있으며, 각각의 장단점이 존재한다. (고정된 파라미터)




Method 1 : 맨 위의 행 픽셀 늘리기 방법은 확실한 방법이나 시야각을 줄이고 중앙 차선 이외의 경로를 추적할 수 없다.
Method 2: 상대적 해상도가 낮은 상단 가장자리의 원 이미지에서 사용 가능한 모든 픽셀을 보존하기 때문에 나은 방법으로 여겨짐.
- Curve fitting : 탐지된 차선 픽셀 P는 곡선을 fitting 하기 전에 H-Net에서 출력한 변환 행렬을 사용하여 변환된다.

- Loss Function : 차선 pixel로부터 최적의 다항식을 찾기 위해서 다음의 loss function을 적용하였다. p*H = p'*이며, p는 p = [x, y, 1] T이고, H-Net의 결과를 통해서 p'으로 변환시킨다. 투영된 점들은 최소 제곱 closed-form solution을 통해 피팅하게 된다.

- 이러한 경우 2차 다항식을 의미하며, 우리에게 주어진 x'* 예측은 y' location에 의해 평가된다.


- Network architecture

Result
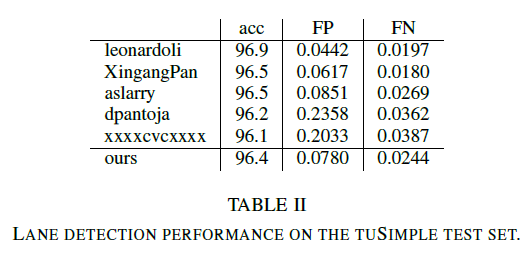


참고 자료
[1] Towards End-to-End Lane Detection: an Instance Segmentation Approach, arxiv.org/abs/1802.05591
[2] A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, ENet: A deep neural network architecture for real-time semantic segmentation. CoRR abs/1606.02147, 2016.
[3] bird's eye view : https://nikolasent.github.io/opencv/2017/05/07/Bird's-Eye-View-Transformation.html
'Image processing > Lane detection' 카테고리의 다른 글
| [2020] RONELD : Robust Neural Network Output Enhancement for Active Lane Detection (0) | 2020.11.10 |
|---|---|
| RESA : Recurrent Feature-Shift Aggregator for Lane Detection (0) | 2020.10.03 |
| [2019] Lane Detection and Classification using Cascaded CNNs (0) | 2020.07.26 |
| Tusimple Dataset-Class (0) | 2020.07.25 |
| [2020] Ultra Fast Structure-aware Deep Lane Detection (0) | 2020.07.21 |