[Abstract]
pixel-wise Segmentation in real time에서 큰 숫자의 floating point operation은 단점으로 여겨지며, 긴~ run-times로 인해 작동능력을 방해한다. 본 논문에서는 낮은 latency 연산으로 구성된 새로운 딥 뉴럴 네트워크 구조를 제안하였다. E-Net은 기존 대비 18배 이상 빠르며 75배 보다 적은 FLOPS, 79배 적은 파라미터 값을 가지고, 기존 모델에 비해 더 나은 정확도를 보이고 있다. CamVid, Cityscapes, Sun 데이터 셋에서 좋은 성능을 보였으며, 정확도와 네트워크 처리 속도 사이의 Trade-off가 존재한다. 우리는 임베디드 시스템에서 제안된 아키텍처의 성능측정을 제시하고, ENet을 더 빠르게 만들 수 있는 개선방안을 제안한다.
[Introduction]

현재, 낮은 전력을 소모해야하는 모바일 디바이스에서는 Real-time Segmentation이 필요하며 증강현실이나 자율주행 분야에서 많이 응용되고 있다. semantic segmenation에서는 픽셀단위로 객체 클래스를 분류하기 때문에 연산량이 많이 들며, 기존의 연구의 경우 battery power에서나 처리속도 면에서 사용할수 없는 경우가 많다.
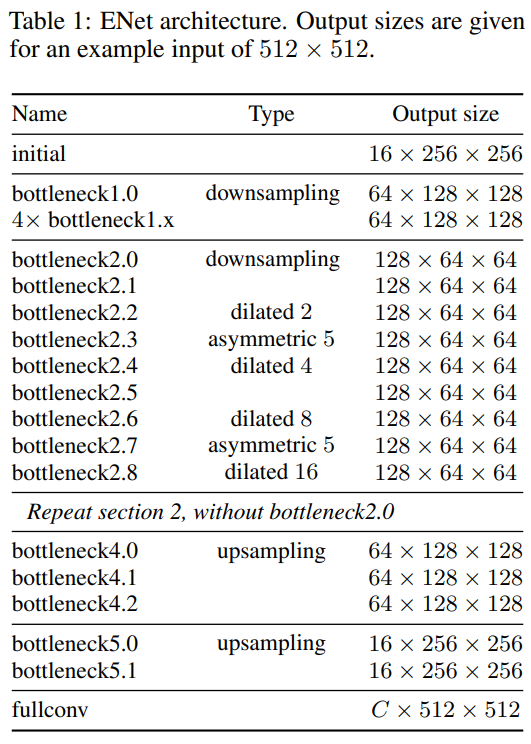
본 논문에서는 빠른 처리 속도와 높은 정확도로 최적화된 신경망을 제안하였다. Post processing을 수행하지 않았고, Compact한 Encoder-Decoder 구조의 빠른 처리속도를 보이고 있다. 제안된 방법은 Cityscapes, CamVid, SUN 데이터 셋에서 평가되었으며 NVIDIA Jetson TX1과 NVIDIA Titan X GPU 환경에서 실험하였다.
[Network architecture]
네트워크의 구조는 Table 1과 같다. 결과 크기는 512x512이며, 본 논문에서 사용하는 initial block과 bottleneck block은 다음과 같다.

Initial block : MaxPooling은 2x2의 겹치지 않는 연산을 수행하고, 13개의 convolution연산과 16개의 특징맵을 결합(Concat) 후 합산한다.
bottleneck : 각 블록은 3개의 컨볼루션 계층을 가진다. Batch Normalization와 PReLU는 모든 컨볼루션 연산 사이에 두고 있다.
- 1x1 conv를 통한 차원 축소
- main conv(regular, dilated, full convolution(a.k.a deconvolution)
- 1x1 conv를 통한 차원 확대
- Downsampling인 경우, max pooling 연산이 main branch에 추가되며, 1x1 projection 컨볼루션을 대신하여 stride 2의 2x2 컨볼루션을 대체하고, zero pad 활성화를 수행한다.
- Asymmetric인 경우, 5x5 컨볼루션을 5x1과 1x5 컨볼루션의 연속으로 대체하였다.
- Regularizer는 spatial dropout을 사용하는데, bottleneck 2.0 이전에는 p=0.01, 이후에는 0.1로 설정하였다.
Encoder에서 Stage 1은 5개의 병목 블록으로 구성되어 있고, 2단계와 3단계도 동일한 구조를 가지고 있다. 단 3단계는 처음에 입력을 다운샘플링 하지 않는다. Stage 3 단계까지 인코더이며, 4단계와 5단계는 디코더에 해당한다. Decoder에서는 max pooling은 max unpooling으로 대체되고, padding은 bias가 없는 spatial convolution으로 대체된다.
[Design Choices]
Feature map resolution : Down-sampling에는 두가지 주요 단점이 있다. 첫째, 특징맵 해상도를 줄이면 가장자리 부분의 공간정보를 손실하게 된다. 둘째, 전체 픽셀 분할은 출력이 입력과 동일한 해상도를 가져야 한다.
첫째 문제는 인코더에 의해 생성된 피처맵을 추가하여 FCN에서와 같이, max-pooling layer에서 선택된 요소의 인덱스를 저장하고 이를 사용하여 디코더에서 sparse 업 샘플링 된 맵을 생성하는 방법을 사용하였다. 여전히, 정확도가 낮아지는 문제가 있지만 가능한 한 제한적인 영향을 주도록하였다. 그러나, 다운 샘플링 연산은 더 큰 receptive field를 가지기 때문에 더 많은 context 정보를 얻을 수 있다. 예를 들어, 도로 장면에서 라이더와 보행자 같은 클래스를 구분하려 할 때, 사람의 외모만을 학습하는 것만큼이나 맥락을 학습하는 것도 중요하기 때문이다.
Early downsampling : real-time 연산에서 가장 중요한 것은 입력 프레임에 대해 효율적으로 처리하는 것이며, E-net의 처음 두 블록은 입력 크기를 크게 줄이고 작은 특징 맵 세트만 사용합니다.
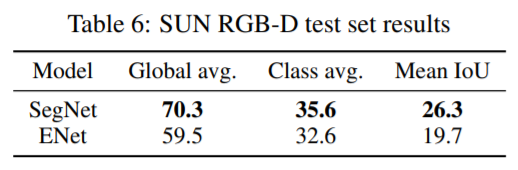
Decoder size : SegNet에서와 같이, 대칭적인 구조를 가지며 인코더의 경우 더 작은 해상도 데이터에서 작동하고 정보 처리 및 필터링을 제공 할 수 있어야 한다. 반면, 디코더의 역할은 인코더의 출력을 업샘플링하고 세부 사항만 미세 조정하게 된다.
Nonlinear operations : 최근 ReLU와 batch normalization을 사용하는 것이 유익하다고 보고되어 있으며, 네트워크 초기 계층에서 대부분의 ReLU를 제거하면 결과가 향상된다는 사실을 발견했다. 또한, 음의 기울기를 학습하기 위해, ReLU 대신에 PReLU를 사용하여 기울기를 학습하도록 하였다. PReLU의 가중치 분포는 그림 3과 같다.

Information-preserving dimensionality changes : 입력에 대하여 조기에 다운샘플링해야 하지만 과도한 차원 축소는 정보흐름을 방해할 수도 있다. 이 문제에 대한 접근법은 pooling을 수행한 다음 컨볼루션을 수행하여 차원을 확장하는 것과 같이 상대적으로 저렴하지만 특징 표현 병목현상이 발생한다. 반면에, 많은 컨볼루션 사용후 pooling은 계산비용이 많이 듭니다. 따라서, stride 2의 컨볼루션 연산과 pooling 연산을 수행하고 특징 맵을 연결하기로 결정했다. 이 기술을 통해 추론 시간을 10배 빠르게 할 수 있었다.
Factorizing filters : n x n 컨볼루션 연산을 n x 1과 1xn 으로 나누어 수행할 수 있으며, 중복연산을 피할 수 있다. 또한, 병목 모듈에서 사용되는 연산은 하나의 큰 컨볼루션 레이어를 낮은 순위 근사치인 더 작고 간단한 작업으로 분해하는 것으로 볼 수 있다. 이러한 분해는 속도를 크게 높이고 매개 변수의 수를 크게 줄여 중복성을 줄일 수 있다. 또한 레이어 사이에 삽입되는 비 선형 연산 덕분에 계산 기능을 더 풍부하게 만들 수 있다.
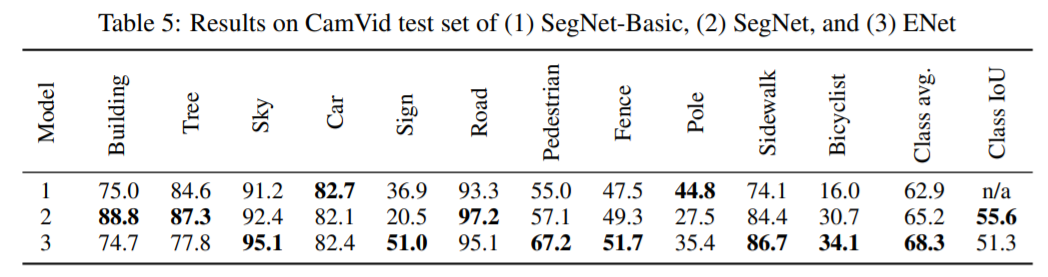
Dilated convolution : 넓은 수용 필드를 갖는 것이 매우 중요하며, 더 넓은 Context를 고려하여 분류를 수행할 수 잇다. 특징 맵을 과도하게 다운 샘플링하지 않고 개선하기 위해 확장된 convolution을 사용하기로 결정하였다. 가장 작은 해상도에서 작동하는 컨볼루션 연산을 대체하였으며, 추가 비용없이 Cityscapes의 IoU를 4% 높여 정확도를 크게 향상 시켰다.
Regularization : 대부분의 픽셀 단위 분할 데이터 세트는 상대적으로 작기 때문에 신경망과 같은 표현모델이 빠르게 과적합되기 시작한다. 초기 실험에서 L2 weight decay를 사용했고, 확률적 깊이(stochastic)를 시도하여 정확도를 높였다.
우리는 컨볼루션 브랜치 끝에 spatial dropout을 배치했는데, 확률적 깊이보다 훨씬 더 작동하는 것으로 나타났다.
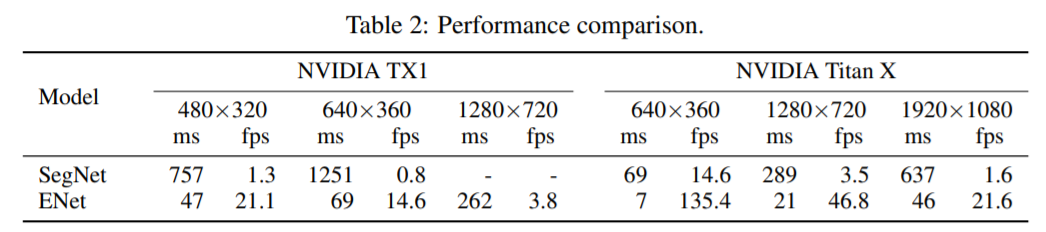
[결과]
Titan X GPU를 사용하고 있으며, NVIDIA TX1 보드에서 640x360를 입력으로 10fps 의 성능을 보였다.

벤치마크 데이터 : Cityscapes, Camvid, SUN RGB-D