참고 자료
[1] Pytorch로 시작하는 딥러닝, 비슈누 수브라마니안 지음, 김태완 옮김
신경망에서 기본 블록으로 사용되는 주요 컴포넌트를 구현해 보았으며, 대부분의 딥러닝 구조는 이러한 큰 틀을 벗어나지 않는다. 각각의 의미를 파악하고, 구조에 대해 미리 학습해보자.
1. 첫 신경망에서의 데이터 준비, 데이터 로딩
2. 학습 파라미터 생성
3. 신경망 모델(네트워크 구현, 오차함수, 신경망 최적화(옵티마이저))
1. 첫 신경망에서의 데이터 준비, 데이터 로딩
첫 신경망 코드에서 get_data 함수는 변수 2개를 다음과 같이 생성합니다.
def get_data():
train_x = np.asarray([1.1,2.2,3,4,5,6,7,8.999,9.555])
train_y = np.asarray([2.2,4.5,4,6,8.245,7,9,1,2.5])
dtype = torch.FloatTensor
x = Variable(torch.from_numpy(train_x).type(dtype),requires_grad = False).view(9,1)
y = Variable(torch.from_numpy(train_y).type(dtype),requires_grad = False)
return x,ynp.asarray : 특정 입력에 대하여 array로 만들어줍니다. 기존의 np.array()와는 달리 이미 유사한 데이터 형태(data_type)의 ndarray가 있다면 복사를 하지 않습니다. 다만, 데이터의 형태가 다른경우에만 복사가 됩니다. (예를 들어, dtype이 'int32'인 array가 있는데, 이를 'float32'인 값으로 변형할때 복사)
dtype : 데이터의 형태를 나타냅니다.
Variable : 변화도를 계산할수 있는 tensor를 의미하며, requires_grad를 통해 True와 False로 지정할 수 있습니다. Tensor와 거의 유사하지만, 차이점은 연산그래프를 정의할 때 자동으로 변화도를 계산할 수 있다는 것입니다.
torch.from_numpy() : numpy 배열을 입력받아, Tensor(dtype)로 바꿀때 사용합니다.
.view() : 텐서의 형상을 변환할 때 사용합니다. 순서대로 (x.shape, y.shape, x, y)의 결과를 출력해봤습니다.

2. 학습 파라미터 생성
예제로 사용하는 신경망은 학습 파라미터로 w와 b로 구성되고, 고정 파라미터로 x와 y로 구성된다. 함수 get_data()는 입력 데이터 x와 y를 만들고 학습 파라미터는 임의의 값으로 초기화해 만들며 학습 파라미터에서는 requires_grad = True 로 설정한다.
def get_weights():
w = Variable(torch.randn(1), requires_grad = True)
b = Variable(torch.randn(1), requires_grad = True)
return w,b
requires_grad를 통해 w와 b에 대하여, 자동으로 변화 가능한 Tensor로 설정
3. 신경망 모델(네트워크 구현, 오차함수, 신경망 최적화(옵티마이저))
앞에서 Variable 객체로 모델의 입출력을 만들었다. 기존의 방법에서는 합수 입력을 처리해 의도한 값을 반환하는 로직을 개발자가 직접 설계한 반면 딥러닝과 머신러닝은 이 로직을 학습시켜 만들어 낸다. 선형 관계는 y = wx+b로 표현되고, 여기서 w와 b는 학습 파라미터를 나타낸다. 입력데이터에 대한 그래프는 다음과 같다.
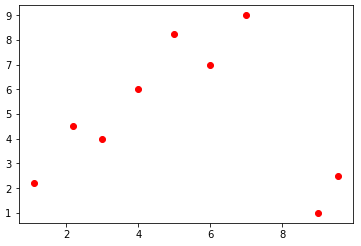
네트워크 구현 및 오차함수
def simple_netwokr(x):
y_pred = torch.matmul(x,w)+b
return y_pred
def loss_fn(y,y_pred):
loss = (y_pred-y).pow(2).sum()
for param in [w,b]:
if not pram.grad is None: param.grad.data.zero_()
loss.backward()
return loss.data[0]모델의 경우 단순한 선형함수로 구성하였다. 네트워크에서는 y의 값을 예측하였다. 이제는 예측결과가 얼마나 정확한지 판단해야 하며, 이 정확도는 loss 함수에서 측정된다. 오차함수는 현재 회귀문제를 다루고 있기 때문에 SSE(Sum of Squared Error)라는 오차함수를 사용해봤다. 기존의 torch에서는 MSE, Cross-Entropy와 같은 여러 오차함수가 이미 구현되어 있으니 참고해서 사용하면 된다.
신경망의 최적화
def optimize(learning_rate):
w.data -= learning_rate * w.grad.data
b.data -= learning_rate * b.grad.dataloss의 backward 함수를 호출해 기울기를 계산했다. 이 프로세스는 한 epoch, 전체 데이터 셋에 대해 반복되며 최적화 한다. 오차가 계산되면 이를 줄이기 위해 계산된 기울기 값을 이용해 학습 파라미터를 최적화 한다. Adam, RmsProp, SGD와 같은 다양한 옵티마이저가 이미 구현되어 있으며 torch.optim 패키지에서 이용할 수 있다.
다음은 입력데이터에 대해 학습한 모델을 나타낸다.
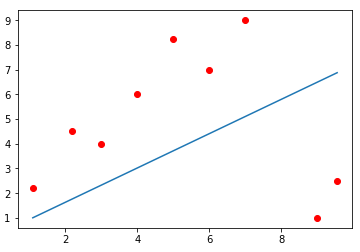
요약 및 정리
딥러닝 네트워크의 주요 컴포넌트들에 대해 알아보았으며, 각각의 컴포넌트들이 가지는 의미를 파악하여 전체적인 모델을 이해할 수 있다. 데이터 준비 단계에서는 알고리즘에 사용될 Tensor 객체를 만들어 봤다. 간단한 네트워크 모델을 만들어 학습하였고, 오차함수를 사용해 모델의 표준을 확인하고, optimize 함수를 사용해 모델의 학습 파라미터를 조정함으로써 모델의 성능을 향상 시켰다.
다음 장에서는 신경망과 딥러닝 알고리즘이 어떻게 작동하는지 깊이 있게 살펴보고자 한다.
'Image processing > Deep-learning' 카테고리의 다른 글
| [Deep Learning] 입력 데이터에서 데이터 정규화를 하는 이유 (0) | 2020.01.07 |
|---|---|
| [Pytorch] 선형 레이어와 비선형 레이어 (0) | 2019.12.26 |
| [Deep Learning] 확률적 경사 하강법(Stochastic Gradient Descent) (0) | 2019.12.10 |
| [Deep Learning] 배치 경사 하강법(Batch Gradient Decent) (0) | 2019.12.10 |
| [Pytorch] 차원에 따른 Tensor (0) | 2019.03.24 |